Bonjour,
Aujourd’hui,
je vais vous montrer comment créer, configurer, sauvegarder et répliquer des
bases de données sur des SGBD (Systèmes de Gestion de Base de Données) tels que
MySQL et PostgreSQL.
Mais
tout d’abord,
Qu’est-ce que La
Réplication de base de données ?
La
réplication des bases de données est un processus de partage d’informations
entre deux ou plusieurs sources de données de façon unidirectionnelle (on parle
alors d’architecture de réplication Master-Slave) ou bidirectionnelle (réplication
Master-Master) pour assurer la fiabilité, la tolérance aux pannes et la
disponibilité des données à tout moment. La sauvegarde et la réplication des
données s’avèrent très utiles dans plusieurs secteurs d’activités et des
institutions où les données sont très sensibles et leurs importances capitales
voir même vitales, s’agissant des institutions bancaires par exemple pour
éviter qu’une défaillance ou panne quelconque du système ne réinitialise les
soldes des comptes de tous les client à zéro 😅 ou encore une perte des informations relatives aux clients d’une
société de télécommunication allant des simples renseignements comme leur nom,
prénom, numéro de téléphone, ..., mais aussi le montant de leur crédit de
communication, ou encore de leur forfait internet pour ne citer que ces
exemples. Enfin, il faut également noter que la réplication des données peut être
utilisée dans un but de répartition de charge entres plusieurs nœuds (serveurs)
distants ou pas ce qui permet d’améliorer les performances du système et de
réduire le temps d’attente des réponses du serveur.
Maintenant
que vous en savez un peu plus sur le concept de réplication des bases de
données, nous allons entrer dans le vif du sujet.
(Ps: dans cet article, les configurations s’effectuent sur la
dernière version à ce jour du SGBD PostgreSQL, soit la version 12 et sur la
version 5.7 du SGBD MySQL, concernant ce dernier la configuration reste
‘‘pratiquement’’ la même sur les versions antérieures et suivantes.)
Configuration de la
réplication sur PostgreSQL
Considérons
que l’on souhaite configurer un mécanisme de réplication de données entre deux
serveurs de bases de données bien distinct, un serveur de base de données dit ‘‘principal’’ ou
‘‘primaire’’ et un autre serveur dit ‘‘secondaire’’ de sorte que les données
présentes sur le serveur primaire soient également présent, disponible à tout
moment et en temps réel sur le serveur de base de données secondaire comme
représenté sur le schéma suivant :

Pour se faire, nous allons commencer par préparer
l’environnement d’installation de notre futur serveur de base
de données PostgreSQL avec cette combinaison de
commande « wget --quiet -O - https://www.postgresql.org/
media/keys/ACCC4CF8.asc | sudo apt-key add - sudo sh
-c 'echo "deb http://apt.postgresql.org/pub/repos/apt/
`lsb_release -cs`-pgdg main" >>
/etc/apt/sources.list.d/pgdg.list' » :

Ensuite,
via la commande « apt-get install postgresql
postgresql-contrib pgadmin4 pgadmin4-apache2 », nous allons installer
le système de gestion de base de données PostgreSQL ainsi que l’outil pgadmin4 qui permet
d’administrer de façon graphique et à travers un navigateur web les bases de
données de PostgreSQL ;

Au
cours de l’installation des packages précédemment définis, deux fenêtres
s’ouvrent à tour de rôle et nous invite respectivement à renseigner l’identifiant
de connexion (login) et le mot de passe de connexion (password) pour accéder à
l’outil pgadmin4
depuis un navigateur web,


Une
fois l’installation de PostgreSQL terminée, nous devons opérer une configuration
minimale à travers la définition du mot de passe de l’utilisateur par
‘‘défaut’’ de PostgreSQL qui est ajouté automatiquement au système lors de la
création de ses paramètres, cet utilisateur de PostgreSQL s’appelle postgres ; pour
ce faire, nous devons entrer la commande « su
– postgres », pour nous connecter à l’utilisateur postgres, puis
entrer la commande « psql » pour
accéder à l’interface de ligne de commande de PostgreSQL, ensuite, avec la
commande « \password postgres » on
défini le mot de passe de l’utilisateur postgres, enfin on quitte l’interface de
ligne de commande de PostgreSQL ainsi que la session de l’utilisateur postgres
respectivement avec les commandes « \q » ou « exit »
et « logout » ou « exit ».

Il
ne nous reste plus qu’à prendre connaissance de l’adresse IP de notre serveur
de base de données et de nous rendre sur un navigateur web pour indiquer cette
dernière suivie de /pgadmin4, soit
dans notre cas nous allons donc entrer l’adresse 192.168.43.123/pgadmin4 pour accéder
à la page d’authentification de l’interface graphique de notre outil pgadmin4 :

Après
avoir renseigné les identifiants conformes de connexions (login et mot de passe),
nous avons la possibilité de choisir la langue de navigation au sein de pgadmin4, et une
fois tous les paramètres renseignés à notre convenance, nous cliquons sur le
bouton Login
pour enfin nous connecter.

Arrivé
à la page d’accueil de notre outil pgadmin4, pour créer une nouvelle base de données, nous devons au
préalable poursuivre certaines étapes essentielles, nous devons commencer par
ajouter un ‘‘Serveur’’, pour ce faire, nous devons cliquer au niveau du
menu contextuel Servers respectivement sur les options
Créer et Serveur ;

Puis,
nous renseignons les informations de notre serveur telles que le numéro de port
(5432 par défaut), le nom de l’utilisateur ainsi que le mot de passe associé, …,
une fois toutes les informations remplies, on clique sur le bouton Enregistrer pour
sauvegarder la configuration.

Après
avoir créé notre nouveau serveur, nous pouvons maintenant ajouter une nouvelle
base de données, pour ce faire, nous nous rendons au niveau de l’onglet du
serveur précédemment enregistré et nous sélectionnons à la suite les options Créer et Base de données…

Ensuite,
avant de valider sur le bouton Enregistrer, nous renseignons les informations de notre future base
de données à savoir son nom et celui du propriétaire, nous disposons également
d’une zone de commentaire pour apporter des précisions sur notre base de
données :

Nous
poursuivons cette fois-ci en définissant un schéma pour notre base de données
nouvellement créée, en sélectionnant tour à tour les options Créer et Schéma au niveau
de l’onglet Schémas
du menu de notre base de données ;

Enfin,
après avoir renseigné les informations au sujet du schéma de notre base de
données nous cliquons sur le bouton Enregister.

Maintenant
que nous avons paramétré au préalable le serveur de contenance de la base de
données ensuite la base de données elle-même puis le schéma de la base de
données, il ne nous reste plus qu’à créer une table dans notre nouvelle base de
données, pour ce faire nous sélectionnons les options Créer et Table… de l’onglet Tables dans la
section Schémas
de notre base de données :

Dans
la section General
nous renseignons le nom de la table, le propriétaire et le schéma
d’appartenance, ainsi que le nom des champs accompagné du type de données et de
la clé primaire de la future table dans la section Colonnes avant de cliquer sur le
bouton Enregistrer.


Et
pour terminer, nous nous rendons au niveau de notre table ‘‘Client’’
nouvellement crée et nous sélectionnons les options Afficher/Éditer les données puis Toutes les lignes,
pour pouvoir ajouter des enregistrements (données) au sein de notre table
‘‘Client’’.


À
présent que notre serveur de base de données PostgreSQL est bel et bien installé
et fonctionnel, si nous souhaitons effectuer une sauvegarde de toute la
structure des tables, schémas et bases de données compris à l’intérieur, généralement
le contenu des bases de données se trouve dans le répertoire /var/lib/postgresql/12/main :

Nous
pouvons avoir recours à l’outil rsync.
Qu’est-ce que
Rsync ?
Rsync
pour Remote Synchronization, soit synchronisation distante est un logiciel
libre de synchronisation des données (répertoires, documents, fichiers, …),
utilisé pour effectuer des sauvegardes incrémentielles, ce qui signifie que
lorsque la copie est effectuée avec rsync, ce dernier compare l’état des données de la source et de la
destination et n’envoie vers la destination que les données manquantes ou altérées
(modifiées) sans écraser (remplacer) les données déjà existantes ; ce qui
a pour répercussion un gain de temps, le maintient de la performance au sein du
réseau et pour se rassurer qu’entre la source et la destination le contenu des
données soit identique à tout moment, on peut en plus associer rsync à un
mécanisme de sauvegarde automatique à une période donnée (on y revient plus
tard 😉).
Pour
effectuer la sauvegarde complète du contenu de notre serveur principal de base
de données PostgreSQL (la source) avec l’aide de l’outil rsync sur un autre
serveur qui nous fait office de serveur de base de données secondaire (la
destination),

Au
niveau du serveur de destination, après avoir créé le répertoire qui va faire
office de dossier de stockage de la sauvegarde du contenu des bases de données
du serveur PostgreSQL primaire, nous entrons la commande « rsync -avz --progress nom_emetteur@adresseIP_emetteur:/chemin_repertoire_
source /chemin_repertoire_destination » ,
une fois cette commande validée, nous devons renseigner le mot de passe associé
au compte utilisateur avec lequel la connexion s’établit sur le serveur source
(c’est une mesure de sécurité pour s’assurer que seuls ceux qui en ont
l’autorisation peuvent accéder au serveur en question), et lorsque cette étape
est réalisée, la sauvegarde s’effectue bel et bien :

Bien,
maintenant sur notre serveur secondaire nous disposons d’une copie complète du
contenu de notre serveur de base de données PostgreSQL primaire, cette
sauvegarde peut en cas d’accident sur le serveur principal nous servir de point
de restauration des données (backup) de la base de données endommagé. Par la
suite, dans un souci de rendre cette sauvegarde de manière périodique et
automatique, nous devons dans un premier temps trouver une parade pour que
l’outil rsync
opère une sauvegarde entre les deux serveurs sans qu’aucun mot de passe ne lui soit
demandé. Pour que le serveur primaire accepte une connexion sans mot de passe
de la part de rsync
effectué sur le serveur secondaire, il faut que le serveur primaire dispose
d’une ‘‘clé publique’’ du serveur secondaire dans sa liste des clés autorisées
à se connecter sans mot de passe. Pour ce faire, nous devons à l’aide de la
commande « ssh-keygen -t rsa -b 2048 » générer
la clé publique sur notre serveur secondaire ;
(Ps: au cours de l’exécution de cette commande, il ne faut surtout pas
entrer de ‘‘passphrase’’ sinon à chaque nouvelle connexion vers le serveur
primaire à partir du serveur secondaire, le ‘‘passphrase’’ va nous être
demandé, pourtant notre but c’est au
contraire qu’on ne nous en demande plus 😅, nous
pouvons également laisser le chemin de destination de création de la clé publique
par défaut.)

Ensuite,
nous devons transférer et ajouter la clé publique nouvellement générée sur
notre serveur secondaire vers notre serveur primaire via la commande « ssh-copy-id -i /repertoire_clepublique nom_récepteur@adresseIP » qui va
en plus d’envoyer la clé vers le serveur primaire, l’insérée également directement
dans son ‘‘trousseau’’ de clés publiques
:

Dorénavant,
si on relance la sauvegarde via l’outil rsync en précisant au sein de la commande
la clé publique précédemment générée, plus aucun mot de passe ne nous est
demandé.

À
présent, comme la connexion entre le serveur primaire et le serveur secondaire
s’effectue sans au préalable renseigner de mot de passe, nous poursuivons avec
l’automatisation de l’opération de sauvegarde via l’outil rsync en créant un
script que nous allons par la suite paramétrer pour une exécution automatique à
une période donnée. Dans le script en question, nous entrons la commande
précédemment exécutée plus haut « rsync -avz
-e "ssh -i /repertoireclepublique" --progress
comptesource@adresseIP:/repertoirebddpostgresql/* /dossierbackup » qui
permet à rsync
de copier les données à partir du serveur principal sans renseigner de mot de
passe ;

Une
fois le script enregistré, nous lui attribuons les droits d’exécution à l’aide
de la commande « chmod u+x script.sh »
et on peut vérifier son exécution avec la commande « ./script.sh » :

Jusqu’à
là nous savons comment nous connecter au serveur primaire depuis le serveur
secondaire sans renseigner de mot de passe, nous avons créé un script qui
effectue l’opération de sauvegarde avec rsync, maintenant comment allons nous
automatiser tout cela ? 😳 facile 😎 ! Comme nous sommes sur un système GNU/Linux, il existe un ensemble
d’outils qui permettent de programmer à l’avance et à une période donnée l’exécution
d’une ou plusieurs tâches, parmi ces outils, on retrouve ce qu’on appel la crontab.
Qu’est-ce que la
Crontab ?
La
crontab
permet de lire et de modifier la liste des programmes (ou tâches Cron) qui sont
exécutés régulièrement sur le système et la période à laquelle ils doivent être
exécutés. Le format typique d’une tâche Cron est le suivant :

Par
exemple, si l’on souhaite qu’une tâche qui consiste à simplement créer un
nouveau fichier nommé test.txt dans le répertoire /home s’exécute à une heure donnée par
exemple 2h30 du matin tous les jours, dans la liste crontab nous allons entrer cette
ligne : 30 2 *
* * touch /home/test.txt, de même, si l’on souhaite que la même tâche
s’effectue plutôt à 6h et à 18h tous les lundis, mercredis et samedis, on doit
à la place entrer cette ligne : 0 6,18 * * 1,3,6 touch /home/test.txt, ou encore l’exécution d’un message à minuit
tous les premiers janvier 0 0 1 1 * echo "Bonne Année!" et enfin si on veut
plutôt l’exécution d’un script toutes les 30 minutes de lundi à jeudi cette
fois-ci, il faut plutôt entrer */30 * * * 1-4 /scripts/script.sh.
Donc
pour ajouter une nouvelle tâche à la liste de notre crontab, nous entrons la commande « crontab -e » puis nous effectuons le
choix 1 ;
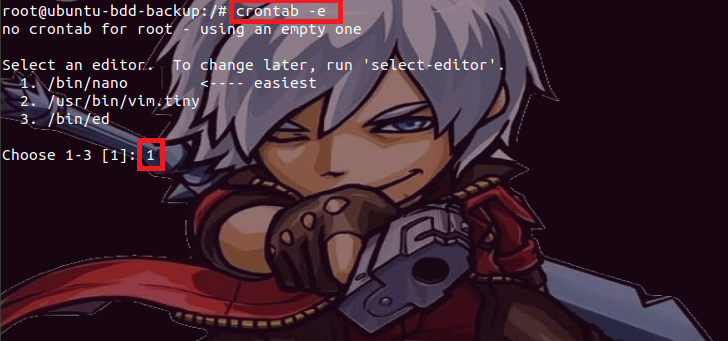
Ensuite,
nous entrons à la fin du fichier la ligne */5 * * * *
/home/ubuntubddbackup/script_bdd_backup.sh pour que notre script effectue une
sauvegarde automatique toutes les 5 minutes du contenu des bases de données de
notre serveur principal PostgreSQL.

Maintenant,
si à la place de la sauvegarde des bases de données PostgreSQL, nous souhaitons
plutôt opérer une réplication des données du serveur de base de données
principal sur le serveur de base de données secondaire, nous devons procéder
comme suit :
(Ps: il est possible d’effectuer différentes types de
réplication sur le SGBD PostgreSQL, on peut citer par exemple la réplication physique,
la réplication logique, la réplication asynchrone
asymétrique, la réplication asynchrone symétrique, la réplication synchrone
asymétrique, la réplication synchrone symétrique, le Warm Standby, le Hot Standby,
le Streaming Replication, BDR, Bucardo,
PgPool-II, Repmgr, Slony … dans notre cas ici nous allons effectuer une
réplication dite de Streaming Replication.)
Pour
configurer notre streaming replication, nous allons commencer par créer un
utilisateur du nom de replication avec son mot de passe associé replication (aussi 😄) via la commande CREATE USER replication WITH REPLICATION ENCRYPTED PASSWORD 'replication' ; à travers
la console de ligne de commande de PostgreSQL sur le serveur principal :

Ensuite,
sur le serveur primaire et sur le serveur secondaire au niveau du fichier /etc/postgresql/12/main/pg_hba.conf,
nous renseignons le nom de l’utilisateur replication et l’adresse IP autorisé à se
connecter sur chacun des deux serveurs, sur l’instance primaire on indique
l’adresse IP du serveur secondaire, et vice versa sur l’instance secondaire on
indique plutôt l’adresse IP du serveur primaire.


Puis,
toujours sur les deux serveurs (principal et secondaire) nous nous rendons au
niveau du fichier /etc/postgresql/12/main/postgresql.conf,
et nous modifions la variable listen_addresses en lui attribuant la valeur '*' pour autoriser
‘‘l’écoute’’ du serveur sur toutes les interfaces IP disponibles, et nous nous
rassurons également que le numéro de port est 5432 (qui est le numéro de port par
défaut du service PostgreSQL) ;


Nous
poursuivons les modifications sur ce même fichier /etc/postgresql/12/main/postgresql.conf en
modifiant cette fois-ci la variable wal_level qui détermine la quantité d’informations écrite dans
les fichiers journaux de transactions en lui attribuant la valeur replica, cette
valeur permet d’écrire suffisamment de données pour pouvoir effectuer de
l’archivage, la réplication et des requêtes :


Toujours
sur le fichier postgresql.conf
des serveurs primaire et secondaire, nous modifions les variables max_wal_senders et
wal_keep_segments qui
permettent d’indiquer respectivement le nombre maximum de serveurs standby
(serveurs secondaires en écoute) et le nombre minimum de journaux de
transactions passés à conserver au cas où un serveur en attente a besoin de les
récupérer pour une réplication ;


Enfin,
nous attribuons la valeur on à la variable hot_standby pour indiquer qu’on peut se connecter sur le
serveur en question et exécuter des requêtes de restauration de données.
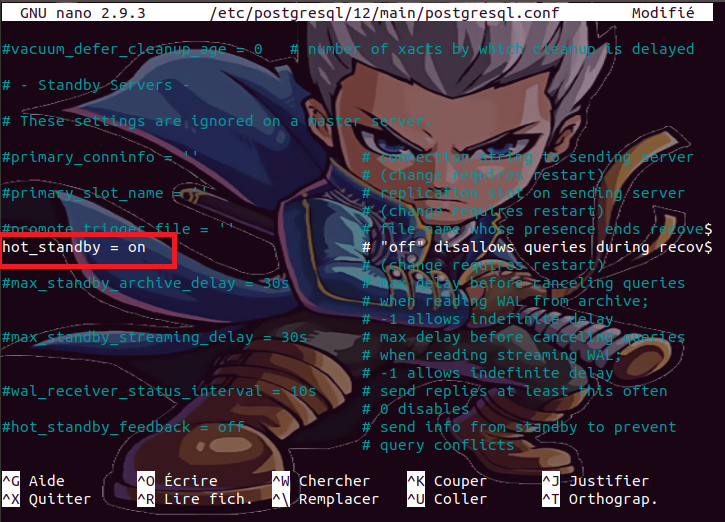

Une
fois ces modifications apportées, nous enregistrons le fichier /etc/postgresql/12/main/postgresql.conf
au niveau des deux serveurs, et nous redémarrons le service PostgreSQL de notre
serveur de base de données principal :

Nous
pouvons nous rassurer que notre serveur principal est bien fonctionnel et fin prêt
à recevoir des connexions sur le port 5432 avec la commande « netstat
-ntaup ».

Bien,
maintenant que notre serveur principal est configuré pour effectuer une
réplication vers le serveur secondaire, nous poursuivons sur ce dernier par un
transfert de l’état actuel des bases de données du serveur primaire
(sauvegarde), pour se faire, nous allons déjà commencer par arrêter le service
PostgreSQL sur notre serveur de base de données secondaire,

Ensuite,
nous allons supprimer l’ensemble du contenu du répertoire /var/lib/postgresql/12/main
du serveur secondaire ;

Puis,
après s’être connecté en tant qu’utilisateur système postgres, à l’aide de la commande « pg_basebackup -h 192.168.43.123 -D
/var/lib/postgresql/12/main/ -U replication -P -R -Xs », nous allons
effectuer une sauvegarde de l’état actuel de l’ensemble des bases de données,
schémas, structure des tables,… de notre serveur de base de données PostgreSQL
primaire vers le serveur de base de données secondaire en se servant de
l’utilisateur replication
avec son mot de passe associé pour effectuer l’opération.

(Ps: pg_basebackup permet de prendre une sauvegarde de base d’une
instance PostgreSQL en cours d’exécution sans affecter les transactions en
cours ou autres opérations et requêtes sur la base de données en question, les
sauvegardes effectuées via pg_basebackup peuvent être utilisées pour une
restauration ou comme le point de départ
d’un serveur en standby comme c’est le cas ici, il faut également noter que les
options employé en paramètre d’exécution de la commande pg_basebackup
permettent pour -D de préciser le répertoire dans lequel la sauvegarde va être
effectué, il est primordial que le répertoire soit vide pour éviter une erreur au
cours de la copie, raison pour laquelle on a supprimé tout le contenu au
préalable 😏, le paramètre -P permet d’activer l’indicateur
de progression de la sauvegarde, -R crée le fichier standby.signal et ajoute
les paramètres de connexion dans le fichier postgresql.auto.conf, et enfin -X
quant à lui indique la méthode suivie d’un ‘‘s’’ signifie que la méthode
appliquée est le Stream pour Streaming Replication.)
Une
fois la sauvegarde terminée, nous pouvons vérifier le contenu du répertoire /var/lib/postgresql/12/main
que nous avons précédemment vidé et nous apercevoir que des données y sont bien
présentes, on va s’intéresser à deux fichiers en particulier : standby.signal et postgresql.auto.conf, standby.signal créé tout à l’heure via le paramètre -R de la commande pg_basebackup, remplace dès la version 12 sur laquelle nous nous
trouvons actuellement, le fichier recovery.conf des versions antérieures, il sert en quelque sorte de balise
indicatrice de serveur en mode ‘‘en attente de lecture des données du serveur
primaire’’ 😀 c’est juste un fichier vide, mais il a toute
son importance dans ce mode de réplication ;
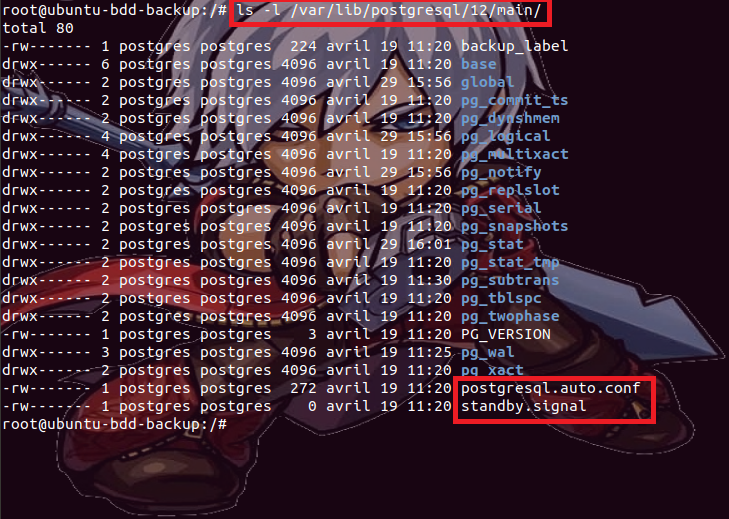
Quant
au fichier postgresql.auto.conf,
il contient les paramètres de connexion (telles que : le nom
d’utilisateur, le mot de passe qui lui est associé, l’adresse IP de l’hôte sur
lequel la connexion doit s’effectuer, le numéro de port d’écoute, …) du serveur
secondaire vers le serveur primaire.

Il
ne nous reste plus qu’à redémarrer le service PostgreSQL de notre serveur de
base de données secondaire pour terminer sa configuration :

Et
comme précédemment sur le serveur primaire en effectuant la commande « netstat -ntaup », nous constatons également
que le port 5432
est bien en écoute d’attente de connexion.

Pour
vérifier le rôle de chacun de nos serveurs (primaire et secondaire) au sein de
la réplication qui vient d’être configurée, il suffit de lancer en tant qu’utilisateur
postgres la
commande « psql -x -c "SELECT * FROM
pg_stat_replication" » sur notre serveur principal,

Et
la commande « psql -x -c "SELECT * FROM
pg_stat_wal_receiver" » sur notre serveur secondaire.

Bien,
maintenant si nous souhaitons vérifier que la réplication des données des bases
de données PostgreSQL est bien synchronisée entre notre serveur primaire et
notre serveur secondaire, nous nous rendons dans un premier temps sur notre
instance primaire, et on entre la commande « psql »
pour passer en mode interface de ligne de commande puis la commande « \l » pour lister l’ensemble des bases
de données présente sur notre serveur :

Nous
retrouvons notre base de données créée plus haut dans l’interface web de l’outil
pgadmin4 : enregistrement_bdd,
c’est sur cette dernière que nous allons effectuer des opérations ;

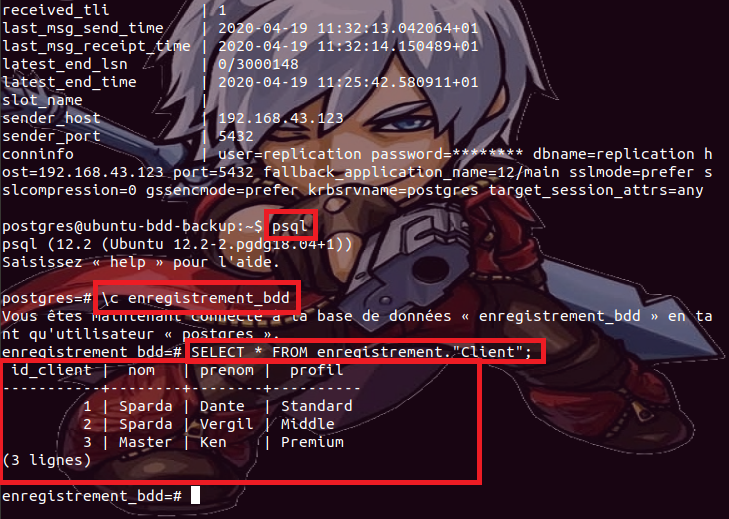
Ensuite,
nous sélectionnons donc cette base de données avec la commande « \c enregistrement_bdd », et pour avoir
accès au contenu de la table Client créé en amont dans la base de données enregistrement_bdd,
on se sert cette fois-ci de la commande « SELECT
* FROM enregistrement."Client"; » :

De
même, sur le serveur secondaire, bien qu’on n’ai pas au préalable créé de base
de données enregistrement_bdd
dessus, mais grâce à la restauration effectuée précédemment via la commande pg_basebackup,
nous avons une sauvegarde des bases de données de notre serveur primaire et les
données sont identiques, raison pour laquelle on peut également retrouver la
base de données enregistrement_bdd
au sein de notre serveur secondaire ainsi que le contenu da la table Client pareil tout
comme sur le serveur principal.
Maintenant,
si on insère un nouvel enregistrement dans la table Client de la base de données enregistrement_bdd
de notre serveur de base de données PostgreSQL primaire,

On
constate que l’enregistrement en question est immédiatement et en temps réel répliquer
sur notre serveur de base de données PostgreSQL secondaire sans aucune autre
opération supplémentaire de notre part.

Par
contre, si nous essayons d’effectuer un enregistrement dans la table Client de la base
de données enregistrement_bdd
depuis notre serveur secondaire, nous allons recevoir un ‘‘petit’’ message d’erreur
qui nous notifie en quelque sorte que la requête ne peut pas aboutir dans un
mode en lecture seule 😅 ;

Donc,
pour le moment, l’écriture des données ne se fait que du serveur principal vers
le serveur secondaire et non pas l’inverse, notre serveur primaire dispose des
droits d’écriture et de lecture alors que notre serveur secondaire ne dispose
que du droit de lecture, nous sommes dans une architecture dite Master-Slave ou
encore une réplication unidirectionnelle, ceci notamment est dû à la présence
du fichier standby.signal
qui ‘‘rétrograde’’ notre serveur secondaire en simple rôle de spectateur. Pour
pouvoir inverser les rôles, enfin que notre serveur secondaire soit en mesure d’insérer
des données au sein de la base de données et de même que ces données soient répliquées
vers le serveur primaire, nous devons sur l’instance secondaire déjà commencer
par masquer la présence du fichier standby.signal soit en le renommant ou en le supprimant,
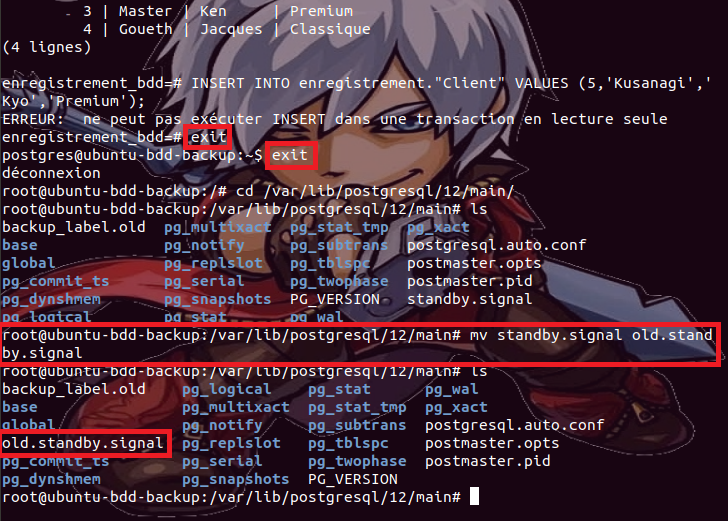
Ensuite,
nous redémarrons le service PostgreSQL sur le serveur secondaire avec la
commande « service postgresql restart »
ou « systemctl restart postgresql ».

Puis,
au niveau du serveur principal, dans le dossier /var/lib/postgresql/12/main, nous allons créer
le fichier standby.signal
(inutile d’écrire quoique se soit à l’intérieur 😊) pour
mettre notre serveur primaire en mode ‘‘écoute’’ pour lire les futures
transactions du serveur secondaire :

Toujours
au niveau du serveur primaire, nous allons cette fois-ci éditer le fichier postgresql.auto.conf
(nous pouvons copier le contenu du fichier postgresql.auto.conf du serveur secondaire,
le coller et juste modifier les variables qui doivent être changées 😉) en lui précisant les paramètres de connexion tels que le
nom d’utilisateur, le mot de passe qui lui est associé, l’adresse IP de l’hôte,
le numéro de port d’écoute, …, pour autoriser le transfert des données provenant
des bases de données du serveur secondaire vers ses propres bases de données en
interne ;

Il
ne nous reste plus qu’a redémarrer le service PostgreSQL pour terminer et
validée notre configuration sur le serveur principal.

Si
nous essayons à nouveau comme précédemment d’effectuer un enregistrement dans
la table Client
de la base de données enregistrement_bdd depuis notre serveur secondaire,

Cette
fois-ci, nous constatons que l’enregistrement est bel et bien pris en compte et
sauvegarder dans la base de données de notre serveur secondaire ;

Et
aussi que l’enregistrement est également transférer (répliquer) vers notre
serveur primaire qui joue cette fois-ci le rôle de serveur standby (en écoute).

Configuration de la
réplication sur MySQL
Maintenant
que notre architecture système de réplication est parfaitement fonctionnelle
sur nos deux serveurs PostgreSQL (primaire et secondaire), intéressons nous à
présent sur la configuration de la réplication des bases de données MySQL.
Comme précédemment, nous allons effectuer les opérations sur deux
serveurs : un serveur principal et un serveur secondaire (d’ailleurs, se
sont les mêmes serveurs utilisés pour la réplication sur PostgreSQL, soit les
mêmes adresses IP).
Sur
le serveur primaire, nous allons commencer par créer la base de données enregistrement ainsi
que la table Client
qui va stocker nos futurs enregistrements soit en langage SQL directement
depuis la console de ligne de commande du serveur ou alors depuis l’interface
web de l’outil phpMyAdmin :
(Ps: en ce qui concerne l’installation et la configuration du SGBD
MySQL et de l’outil phpMyAdmin, bien vouloir consulter mon article sur le sujet
ici.)

Ensuite,
nous renseignons quelques données au sein de la table Client du serveur de base de données MySQL
principal.

Maintenant,
nous effectuons une sauvegarde de la totalité de la base de données enregistrement et
de son contenu sur le serveur principal à l’aide de la commande « mysqldump -u root -p nom_bdd > nom_extraction_bdd.sql »,
et nous transférons via la commande « scp nom_extraction_bdd.sql
nomdestinataire@adresseIP:/chemin_de_stockage » le fichier résultant
de la précédente sauvegarde vers le serveur secondaire ;

Après,
nous nous rendons au niveau du serveur secondaire et actuellement lorsque nous
vérifions en mode interface de ligne de commande de MySQL avec la commande « show databases; » dans la liste des
bases de données disponibles sur notre serveur secondaire, on n’aperçoit pas la
base de données enregistrement
ce qui est tout à fait normal puisque nous ne l’avons pas créé dessus 😁 mais uniquement sur le serveur principal,

Nous
devons donc créer une base de données du nom enregistrement (qui sera ‘‘vide’’ pour
l’instant) sur notre serveur secondaire :

Puis,
avec la commande « mysql -u root -p nom_bdd
< nom_bdd.sql », nous allons importer le contenu du fichier bdd_enregistrement.sql
transféré plus tôt du serveur primaire vers le serveur secondaire dans le but
de mettre au même niveau d’information, les bases de données enregistrement de
nos deux serveurs.

Ainsi,
lorsque nous sélectionnons à nouveau la base de données enregistrement en mode interface de
ligne de commande MySQL dans le but de l’inspecter, nous constatons déjà
qu’elle n’est plus vide et que les enregistrements contenu dans la table Client de notre
serveur secondaire sont identiques à ceux présent au niveau du serveur primaire.

Maintenant,
que nous disposons de deux bases de données identiques entre le serveur
primaire et le serveur secondaire, nous pouvons débuter la configuration de la
réplication de ces bases de données. Sur le serveur principal, nous allons modifier
le fichier /etc/mysql/mysql.conf.d/mysqld.cnf
pour permettre à notre serveur primaire d’écouter sur toutes ses interfaces
réseau et d’autoriser les connexions à ses bases de données depuis des hôtes
distants (connus) en attribuant à la variable bind-address la valeur 0.0.0.0 :

Par
la suite, sur ce même fichier, nous allons définir une valeur unique à la
variable server-id
et nous allons décommenter (retirer le # de) la ligne log_bin = /var/log/mysql/mysql-bin.log pour
activer l’écriture des fichiers de journalisation (les fichiers journaux qui
contiennent les informations sur les modifications apportées à une instance de
serveur MySQL), la variable expire_logs_days
indique le nombre de jours pour la durée de conservation des fichiers journaux
et enfin la variable max_binlog_size
indique la taille maximale que peut atteindre l’espace de stockage de ces
fichiers journaux.
(Ps: la variable server-id peut prendre la forme d’un nombre entier
quelconque, mais doit surtout être unique par fichier de configuration mysqld.cnf
retrouvé dans la chaîne de serveurs utilisés pour effectuer la réplication, il
s’agit d’un identifiant unique pour le serveur MySQL et non pour son rôle en
tant que serveur primaire ou secondaire ou encore Master ou Slave et ce même si
le même serveur occupe les deux rôles à la fois.)

Une
fois toutes les modifications apportées au fichier /etc/mysql/mysql.conf.d/mysqld.cnf, nous
l’enregistrons et nous redémarrons via la commande « service
mysql restart » ou « systemctl
restart mysql », le service MySQL sur notre serveur principal pour
valider les modifications :

Ensuite,
depuis la console de MySQL nous allons entrer la commande « GRANT REPLICATION SLAVE ON *.* TO 'jacquesgoueth'@'192.168.43.248'
IDENTIFIED BY 'password'; » pour autoriser ou donner les droits à
l’utilisateur jacquesgoueth
via son mot de passe associé password de pouvoir répliquer les données provenant du serveur
primaire sur le serveur secondaire ;

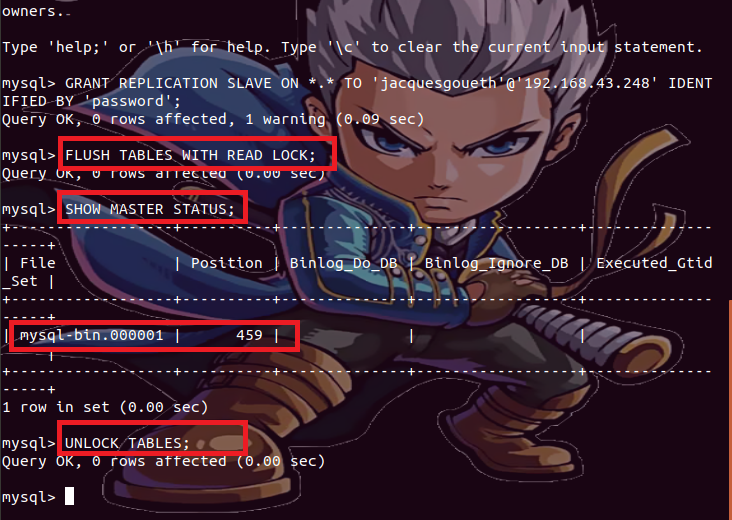
Nous
poursuivons avec la récupération de l’index du log binaire qui va être utilisé
pour la réplication des bases de données, pour ce faire, nous bloquons temporairement
à l’aide de la commande « FLUSH TABLES WITH
READ LOCK; » les écritures sur les bases de données de notre
serveur primaire, puis, nous entrons la commandes « SHOW
MASTER STATUS; », pour récupérer l’index du fichier journal (dans
notre cas ici il s’agit de mysql-bin.000001) et le numéro marqué dans la
colonne Position,
enfin, via la commande « UNLOCK TABLES; »
on déverrouille l’écriture sur les tables des bases de données du
serveur principal et dans ce cas, on doit se rassurer qu’aucune modification ne
soit effectuée jusqu’à la fin de la configuration du serveur secondaire.
(Ps: si on ne peut pas garantir le fait qu’aucune modification ne
survienne sur le serveur principal, nous pouvons également déverrouiller
l’écriture sur les bases de données après avoir au préalable fini de configurer
le serveur secondaire.)
Maintenant,
nous nous rendons sur notre serveur secondaire et dans le fichier /etc/mysql/mysql.conf.d/mysqld.cnf
nous lui attribuons un identifiant unique pour sa variable server-id ;

Une
fois le fichier /etc/mysql/mysql.conf.d/mysqld.cnf
enregistré, nous redémarrons le service MySQL sur notre serveur secondaire,

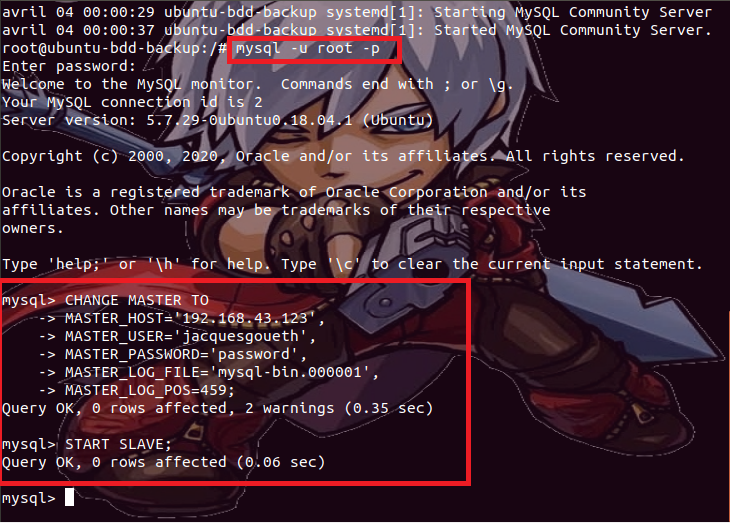
Puis,
nous nous rendons dans la console MySQL de notre serveur secondaire pour
renseigner au travers de la commande « CHANGE
MASTER TO MASTER_HOST='adresseIP_Master', MASTER_USER='nomutilisateur_replication', MASTER_PASSWORD='motdepasse',
MASTER_LOG_FILE='indexlogbinaire', MASTER_LOG_POS=logposition; », les différentes
informations de connexion (telles que l’adresse du serveur à partir duquel les
données doivent être répliquées, le fichier journal de requête qui doit être
consulté, à partir de quelle position dans ce fichier journal, avec quel nom
utilisateur et mot de passe associé la réplication doit être effectuée) nécessaires
pour permettre à notre serveur secondaire de recopier (répliquer) toutes les
données provenant de notre serveur primaire, et enfin, on démarre sur le
serveur secondaire, le processus d’écoute pour la réplication via la commande « START SLAVE; ».
On
peut vérifier le rôle occupé par notre serveur secondaire au sein de la
réplication ainsi que les différentes informations qu’il utilise pour la (la
réplication) mener à bien avec la commande « SHOW
SLAVE STATUS \G; » :

Voilà 😄 ! Nos serveurs primaires et secondaire sont dorénavant configurés
et synchronisés pour effectuer des opérations de réplication de données entre
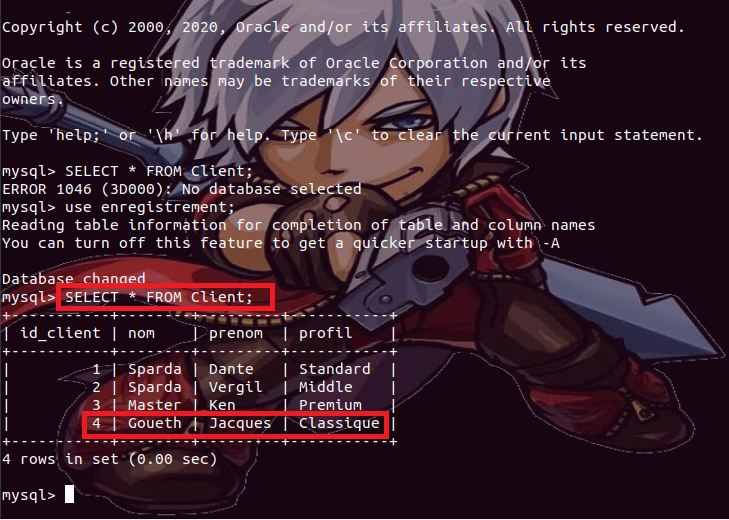
leur base de données respectives, donc par conséquent, si nous insérons un
nouvel enregistrement au sein de la table Client de la base de données enregistrement de
notre serveur principal ;

Nous
constatons qu’en plus d’être normalement sauvegardé au niveau de notre serveur
de base de données MySQL primaire,

L’enregistrement
est également automatiquement et en temps réel recopié (répliqué) sur notre
serveur de base de données secondaire.
Jusqu’à
là notre système de réplication des données entre les bases de données de nos
deux serveurs fonctionne correctement, mais qu’en est-il si l’on souhaite
plutôt que les enregistrements qui doivent être répliquées proviennent de notre
serveur secondaire à destination pour le serveur primaire ? Car
actuellement, la réplication se fait uniquement de manière unidirectionnelle du
serveur primaire vers le serveur secondaire puisque nous sommes en fait dans une
architecture de réplication de type Master-Slave, il se peut que pour certaines
raisons (défaillance technique, panne, coupure réseau, serveur injoignable, …) l’on
désire que les données soient répliquées dans les deux sens (bidirectionnelle) pour
éviter d’éventuelle pertes de données (ce qui peut aussi paradoxalement parfois
provoquer des conflits d’écriture des données si des mécanismes d’automatisation
et de basculement lorsqu’un serveur de base de données est injoignable et
lorsqu’il est à nouveau détecté ne sont pas mis en place en simultané) soit
alors une architecture dite Master-Master. Pour ce faire, nous allons commencer
par promouvoir notre serveur secondaire en deuxième serveur maître MySQL au
sein de notre architecture.
Nous
nous rendons donc au niveau de notre serveur secondaire, puis nous apportons quelques modifications
supplémentaires au fichier /etc/mysql/mysql.conf.d/mysqld.cnf, en y ajoutons la valeur 0.0.0.0 à la
variable bind-address
et en décommentant la variable log_bin ;


Après
avoir enregistré les modifications apportées au fichier etc/mysql/mysql.conf.d/mysqld.cnf,
nous redémarrons le service MySQL, puis nous
allons créer avec les autorisations adéquates un nouvel utilisateur du nom de christiangoueth (avec
son mot de passe associé) qui à l’instar de l’utilisateur jacquesgoueth créé
plus tôt au niveau du serveur principal et employé pour la réplication des
données du serveur primaire vers le serveur secondaire, ce deuxième utilisateur
christiangoueth
quant à lui va plutôt nous servir à effectuer nos transactions de réplication de
données dans l’autre sens, c’est-à-dire du serveur secondaire vers le serveur
primaire :

Ensuite, on
récupère au niveau du serveur secondaire l’index du fichier journal de rapport
des modifications apportées (écriture de nouvelles données, création de tables,
…) ainsi que la position de départ de lecture de données au sein de ce fichier ;

Et
enfin, au niveau de la console MySQL du serveur primaire, à l’aide de la
commande « CHANGE MASTER », nous renseignons
les dernières informations nécessaires
pour achever la configuration de notre mécanisme de réplication
bidirectionnelle et nous la rendons active via la commande « START SLAVE ».


Maintenant,
si nous insérons un nouvel enregistrement au sein de notre serveur de base de
données MySQL secondaire,

Les
données sont immédiatement répliquées vers notre serveur de base de données
MySQL primaire.

Désormais,
nos deux serveurs MySQL sont capables de jouer simultanément le rôle de Master
et de Slave ce qui nous donne comme résultat une architecture de réplication de
type Master-Master. Donc nous pouvons renseigner des enregistrements aussi bien
sur le serveur primaire que sur le serveur secondaire et être rassuré que les
données seront répliquer dans les deux sens : du serveur primaire vers le
serveur secondaire et du serveur secondaire vers le serveur primaire.
À
présent, vous savez comment installer le SGBD PostgreSQL, comment le configurer
et y créer des bases de données depuis l’interface web de l’outil pgadmin4, comment
insérer des données dans des bases de données PostgreSQL et MySQL (via une
interface graphique ou en console de ligne de commandes SQL ou PSQL), aussi comment
effectuer des sauvegardes de fichiers à l’aide de l’outil rsync, rendre ces
sauvegardes automatiques via la crontab, aussi faire une synchronisation entre deux systèmes
GNU/Linux sans entrer de mot de passe au préalable, associé au sein d’un script
un mécanisme de sauvegarde automatique des données, mais aussi comment mettre
sur pied la réplication des bases de données PostgreSQL de type Streaming Replication
et aussi comment promouvoir un serveur de base de données en serveur primaire
ou secondaire et inversement ; nous avons aussi effectué un équivalent des
mêmes manipulations, mais cette fois-ci sur le SGBD MySQL, en configurant dans
un premier temps une réplication de type Master-Slave (unidirectionnelle), puis
une fois terminé en poursuivant avec une architecture de réplication de type
Master-Master (bidirectionnelle).
Merci
d’avoir suivi le tutoriel jusqu’à la fin.
À
très bientôt !!!















Aucun commentaire :
Enregistrer un commentaire